Research
Scene Understanding
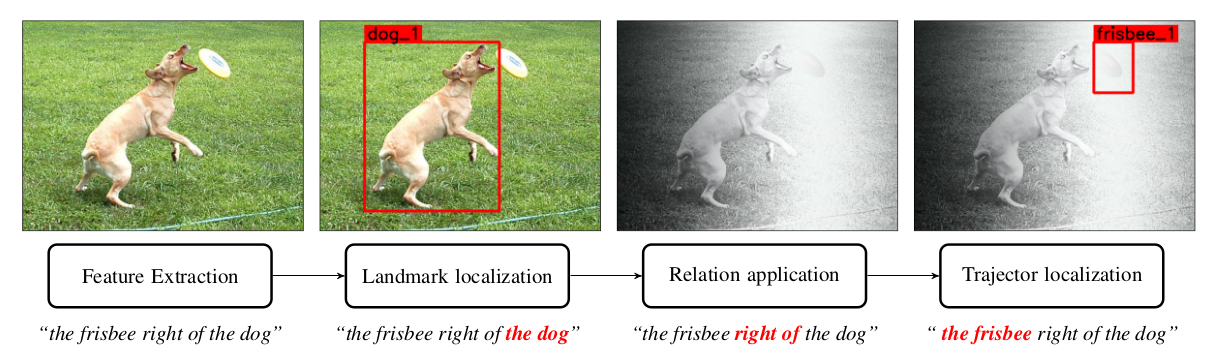
Understanding complex visual scenes is one of fundamental problems in computer vision, but learning in this domain is challenging due to the inherent richness of the visual world and the vast number of possible scene configurations. We propose a unified framework for learning visual representation of words denoting attributes such as “blue” and relations such as “left of”. The strength of our model is that it only requires a small number of weak annotations and is able to generalize easily to unseen situations such as recognizing object relations in unusual configurations. We are able to extend our formalism to gracefully incorporate more complex linguistic concepts such as comparatives (moving faster than) and cardinality (there are three red balls). The formalism can be applied to learn in an online manner in real-time video environments.
Related publication: Few-shot Linguistic Grounding of Visual Attributes and Relations using Gaussian Kernels (2021)
Reinforcement Learning in Robotics
In robotics, an agent is required to control its actuators to perform tasks with its perception through the sensors. Even though low-level PID and path planning algorithms are robust enough to drive the joints to reach their desired positions, but robots are still having huge difficulties in solving high level tasks, such as locomotion, autonomous driving, and object manipulation. With the development of deep learning (DL), deep imitation learning (DIL) and deep reinforcement learning (DRL) have shown many advantages in performing such high-level controlling tasks. However, manipulating deformable objects using data-drive approaches remains a challenging problem due to the highly non-linear nature of the deformable objects.

Digital/Computational Pathology
Computational pathology is a relatively young field which is moving at an incredibly rapid pace. Whole slide images (WSI) are routinely obtained at 40x magnification which incurs with it a substantial file size. Even small datasets can very easily amass to several terabytes of storage. Machine learning techniques can be crafted to, among other things, detect, segment or classify WSIs. In addition to getting patients their crucial diagnoses faster than ever before, these kinds of technologies can provide a reduction to clinician workload and can act as a diagnostic aid for healthcare professionals.
Image Stitching for Medical Imaging
High-resolution fundus cameras are the primary screening tool for diseases such as diabetic retinopathy (DR). While effective, their cost, bulkiness and required training make them impractical for mass screening in low-to-middle-income countries (LMICs). The disproportionate projected rise in DR occurrence combined with the shortage of medical personnel in these places further exacerbates this issue. The Arclight is an affordable, lightweight ophthalmoscope. By affixing the device to a smartphone camera, users can capture videos of the back of the eye. However, The field of view is limited: around 5 degrees. We aim to convert videos of the back of the eye into a single picture, by stitching different video frames to create a wide field image. This research would primarily benefit those living in (LMICs) and those living in remote communities globally.

Micro-Expression Analysis
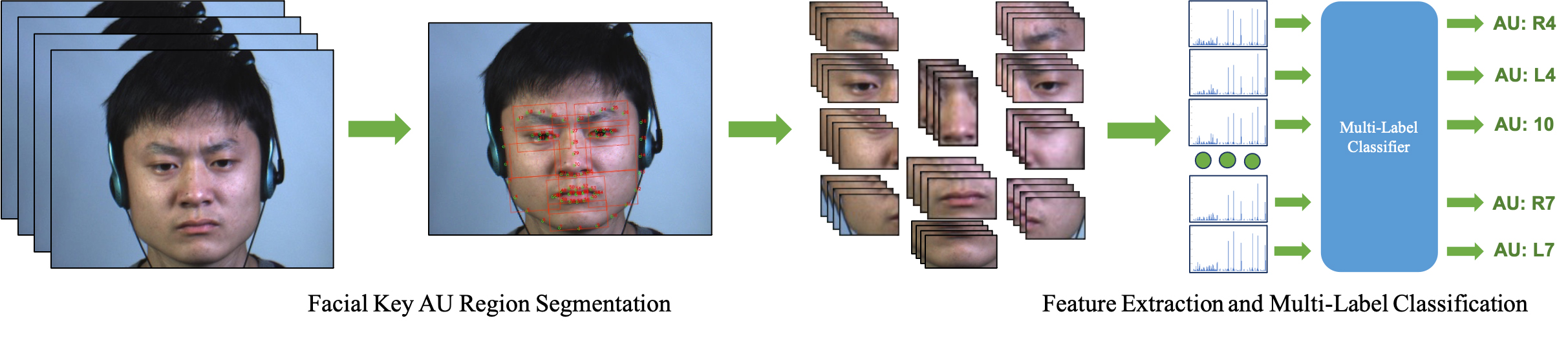
Micro-expressions describe unconscious facial movements which reflect a person’s psychological state even when there is an attempt to conceal it. Often used in psychological and forensic applications, their manual recognition requires professional training and is time-consuming. Facial Action Units (AUs) are a coding of facial muscular complexes which can be independently activated. Each AU represents a specific facial action. We propose a method for the challenging task that is the detection of activated AUs when the micro-expression occurs. We propose a segmentation method for key facial sub-regions based on the location of AUs and facial landmarks, which extracts 11 facial key regions from each sequence of images.
Related publication: Facial Action Unit Detection with Local Key Facial Sub-region based Multi-label Classification for Micro-expression Analysis (2021)
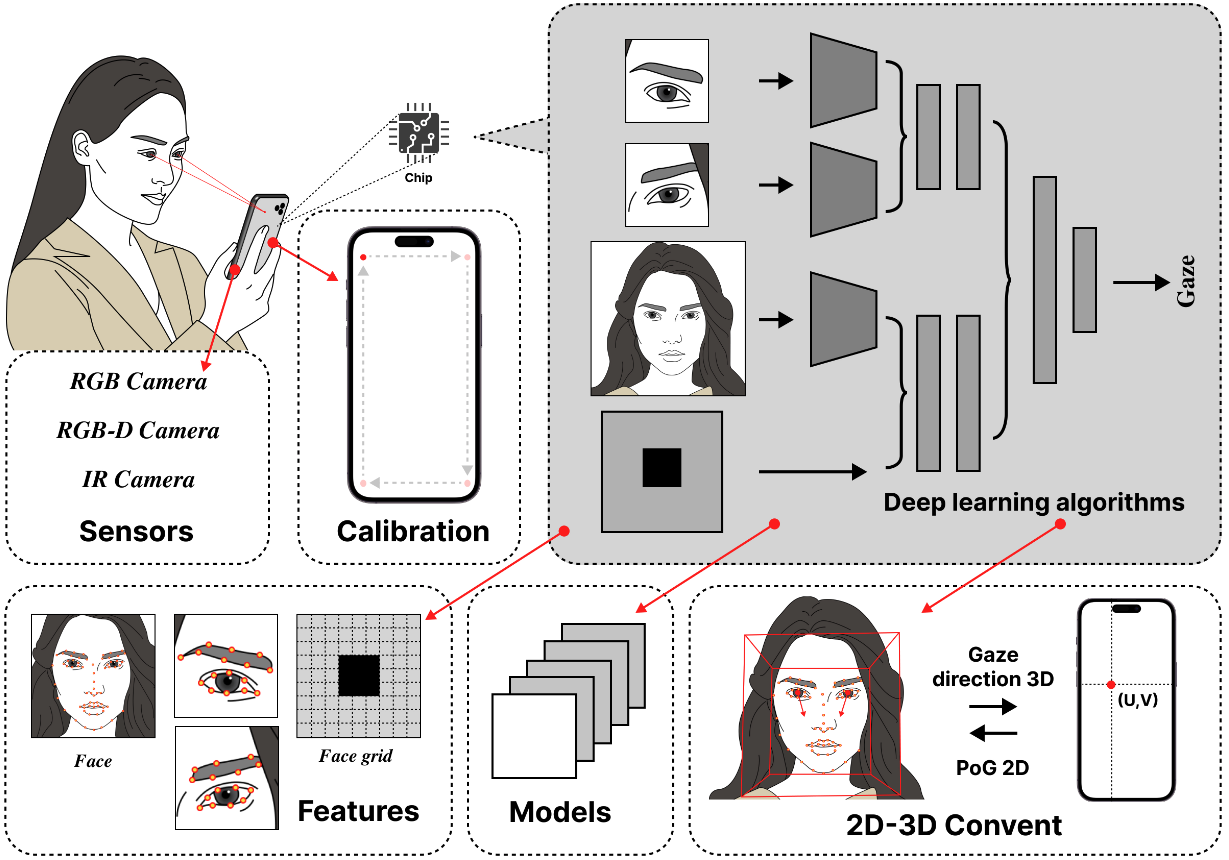
Gaze Estimation
Eye tracking has been widely used in psychology, human-computer interaction and many other fields. Recently, eye tracking based on off-the-shelf cameras has produced promising results, compared to the traditional eye tracking devices. Subtle movements of the eyeball can change the gaze direction dramatically and the difficulty of the task varies greatly across people. The rise of AI methods, such as deep learning approaches, has advanced the use of learning-based gaze estimation methods. Designing useful and usable gaze-aware interfaces is another major challenge. In practice, tracking accuracy and precision vary largely depending on factors such as the tracking environment and user characteristics.
Related publication: An End-to-End Review of Gaze Estimation and its Interactive Applications on Handheld Mobile Devices (2023)